


Peering into the Unseen Protein Universe
Blog summary of our ICLR 2024 Outstanding Paper Award Winner, "Protein Discovery with Discrete Walk-Jump Sampling"


There are something like 20,000 unique proteins in the human body, and our immune system can field a practically infinite roster of different antibody proteins to neutralize molecules that cause disease. Many of the medications discovered over the past few decades are actually antibodies that were harvested from animal (mice, rats, rabbits, etc.) immune systems and engineered to treat and cure human disease. Scientists use DNA sequencing techniques to “see” the DNA that encodes these proteins and come up with starting points for drugs. But because of the infinite variety of proteins that living organisms can produce, and our limited ability to observe these proteins, we only see a small sliver of the accessible protein universe. There are undiscovered cures, treatments, and biological machines hiding in that infinite variety, waiting to be found and engineered and turned against all our most existential problems: pandemic preparedness, climate change, human healthspan. The work summarized in this blog post started with a simple question — how do we find the “missing pieces” of the protein universe?1
Discrete Walk-Jump Sampling (dWJS) is a machine learning method we invented to solve this problem. Our paper won a ton of awards2 for which we’re very grateful, most notably an ICLR 2024 Outstanding Paper Award, where the Awards Committee said:
The authors introduce an innovative and effective new modeling approach specifically tailored to the problem of handling discrete protein sequence data.
In this post I’ll give a high-level overview of what we did and why it matters.
Background on generative modeling
Familiar generative models like Claude and Stable Diffusion generate human-readable natural language or human-understandable images. Less familiar to most is the previously mentioned protein generation problem. Modern generative image models typically use an ML method called diffusion or flow matching to produce hyper realistic, controllable, potentially surprising images like the “astronaut on a horse.” Astronaut and horse are familiar concepts on their own, and a sci-fi western inspired painter might produce an image like this if the mood struck, but a diffusion model produces these strange images on demand. We’re looking for the “astronauts on horses” of the protein universe. We want ML models to learn from the proteins we’ve seen, and remix and recombine them in strange and unpredictable ways, that nevertheless make sense to living cells.
.jpg - Wikipedia")
The name “generative model” implies two things:
(a) It is a model, in this case of a probability distribution p(x), often parameterized by a neural network.
(b) There exists a protocol to sample (i.e., generate) new data so that samples occur with probability proportional to their “true” probability under the distribution p(x).
Energy-based models (EBMs) are a class of generative models that, given an input x, learn to return a so-called “energy” that represents the “likelihood” of x. The “likelihood” here is something similar to a probability except it need not be between 0 and 1. If two inputs are assigned an energy each by the model, the input with the lower energy is considered more likely than its counterpart.
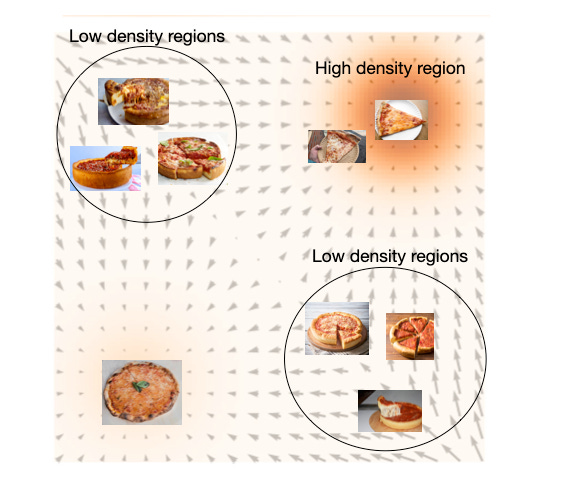
By analogy: suppose you are a connoisseur of New York pizza. That means you know well that you are much more likely to find a delicious thin crust NY slice than a piece of deep dish (aka casserole). Furthermore, you are perfectly aware of the sad truth that the dollar slice is going extinct. Internally, this implies you have learned an energy function that assigns deep dish slices higher energies than thin crust, and in turn dollar slices higher energy than more costly options.
{kind=link}

Score-based models are another class of generative model that is closely related to our friend the EBM. Rather than estimating the energy of an input x, the score-based model tells you how the energy changes as you change x (the score function is the derivative of the energy function). This means that the score-based model is like a compass.
Imagine a smooth transition from a perfect, crispy thin crust NY corner store slice to a sloppy, tomato pie with enough cheese to stop a bullet. The score function will tell you that as you transition from that perfect NY slice, the energies should correspondingly go down at a certain rate.
It turns out that a great way to get ML models to generate images is to train them to “denoise” a noisy image into a clean one, which means figuring out what “direction” an image should “move” (in image space) in order to become more likely.

There’s one more missing ingredient: Neural Empirical Bayes. I’m biased because my good friend and colleague Saeed Saremi wrote this paper (with Aapo Hyvarinen), but it is filled with good ideas and insights. NEB introduced Walk-Jump Sampling - based on a deceptively simple, but effective, idea: generating “clean” real, high-resolution images is hard, so don’t do that. Instead, train a model to “jump” from noisy to clean images, use that model to generate noisy images (which is easy), and then clean them up by jumping back to real images.
The big idea
Can we turn the hard problem of training an EBM on discrete data (protein sequences) into an easy problem by smoothing that data with noise,3 and train a separate denoising model that will give us a good generative model for proteins? This was the underlying question and big idea behind discrete Walk-Jump Sampling (dWJS). The short answer is - yes. In our hands, dWJS turns out to be the ideal sampler for discrete protein sequences, outperforming diffusion models, autoregressive language models, masked language models, and even large language models like ChatGPT, which we adapted for protein design via in-context learning. dWJS outperforms these other approaches on just about any metric we can come up with to measure sample quality and diversity.
dWJS works because we can represent proteins as discrete sequences of 1s and 0s and inject a large amount of noise that blurs the sequence. Then we can teach a model to denoise back to real, clean sequences, and use that model (or train a completely separate generative model trained only on noisy samples) to easily generate blurred, noisy sequences, which can be cleaned up into real sequences again. We generate with Langevin Markov Chain Monte Carlo - which can use either the score-based denoising model or the EBM - which is a powerful algorithm for sampling that works especially well when sampling noisy data, where the algorithm can’t get “stuck” because it’s traversing a highly smoothed space.

Usability is a key metric for deep learning methods, but this is usually something that is felt out by practitioners and spread through word of mouth. The claims of ease-of-use made in a paper oftentimes do not translate to the actual user experience. The argument for usability of dWJS is very straightforward: there is one “hyperparameter” - one thing that the user has to decide - the noise level, that controls the sample quality vs diversity tradeoff. High noise will give “high quality” samples, but they might all start to look alike because the extreme noise blurs out all the fine-grained detail. Low noise will retain more detail and give more diverse samples, but they will be “lower quality.” Diffusion models have many different noise levels that must be tuned, and this makes both training and generation more brittle. dWJS sampling can be done with a single model used for both denoising and generation, or a separate EBM can be trained for sampling noisy data, which we find helps improve sample diversity. The method is deliberately simple and sample efficient, requiring only ~100s of training dataset examples to get started.
What’s the catch?
I recently heard a quote attributed to Andrew Gordon Wilson (maybe AGW can confirm if he originated this):
There is no free lunch, but many people spend too much for lunch.
I think dWJS is a perfect example of this in practice. Diffusion models are great if you have gigantic datasets of approximately continuous data (e.g., images or audio), or if you need to make little changes and tweaks to your outputs to refine them, like we do in our NeurIPS 2023 paper, Protein Design with Guided Discrete Diffusion. Unguided generation with Langevin MCMC is also “mode seeking”, so you will get “natural” looking sequences, but depending on your goals that may not be what you want. But if you are implementing fancy samplers and equivariant protein structure generation architectures, all to show that you can generate novel protein sequences, you are paying waaaaaaay too much for lunch, and your lunch is probably not very good.
Some free research ideas
(Feel free to skip to the next and final section if you are not a researcher and don’t need any free ideas)
Could you use ideas from diffusion and flow matching to address the limitations of dWJS and get the best of both worlds? I think so. You could, for example, take the generative process in our guided discrete design algorithm introduced by Gruver & Stanton, and replace it with dWJS, while keeping our guidance formulation.
You could take dWJS exactly as-is and apply it to different protein design and engineering problems beyond antibodies, or even to a natural language dataset like text8 or TinyStories.
I’m not territorial about research, and my group and collaborators have way too many papers to write (and unsolved problems in drug discovery and ML to work on) to pursue all of the clear opportunities for follow up. So if you’re thinking about logical next steps to anything we’re publishing, there’s a good chance that the playing field is wide open.
If we’re not working on those directions, what are we doing? We’ve already shared some exciting preliminary work led by Sai Pooja Mahajan, extending our approach to sampling in the latent space of pre-trained protein language models, like ESM2 or our own Lobster models. And there is much more on the way.
Where do we go from here?
Have we found any astronauts on horses in the protein universe yet? If you read popular coverage of other protein generative models in the NY Times, you might think the answer is yes. We should certainly be excited and energized by the progress in the field, but as I’ve previously written, the impact of AI and ML in drug discovery isn’t where you think it is. Our work is one very cool and creative (in my opinion), very small, piece of the puzzle. Generative modeling has something to offer biology when it’s used correctly and not over engineered, but it is far from the whole story. In fact, in most applications, what biologists and chemists actually need is discriminative modeling - good predictions about the properties of molecules, with calibrated uncertainties. And even more fundamentally, I think what ML has to offer drug discovery is mostly related to good abstractions, a computational mindset, and better ways to think about data and decision making. We need to continue innovating, building on our own work and the work of the entire research community, to realize the promise of programmable biology.
Resources and contact
Acknowledgements
Thanks to our collaborators and co-authors on this research, especially Saeed Saremi.
This technical post is aimed at both ML researchers and enthusiasts. If you’re a researcher intrigued by what you read here, you can find the math, quantitative results, and details in the paper. I write my papers (and try to influence any paper I am involved with) to be as understandable as possible, not overcomplicate things with jargon, and use notation to clarify the methods and story. So these technical posts are for enthusiasts who aren’t used to reading research papers, or practitioners who want a gentle introduction to the main ideas and results.
Spotlights at ICLR 2023 Physics for Machine Learning, NeurIPS 2023 GenBio, and MLCB 2023 Workshops.
The idea of “smoothing” something with noise might be unfamiliar. It’s most clear for images, where adding noise gives a blurred image. The image loses the fine-grained details first, but retains its overall structure until the amount of noise is too high.
 | A guest post by
|